Tabellen
Allgemeines
In Tabellen werden die Daten gespeichert. Tabellen bestehen aus Spalten und Zeilen.
Die Daten in einen Tabellenfeld einer Spalte müssen den gleichen Datentyp (Zahl, Text, Datum, Währung, Ja/Nein etc. - Details finden Sie in der Online-Hilfe von Access) haben.
Die Felder einer Tabellenzeile bilden den Datensatz (Recordset).
Der Tabellenentwurf
In der Entwurfsansicht der Tabelle lassen sich Spalten und die zugehörigen Felder definieren. Wichtigste Entscheidung ist der Datentyp (Text, Memo, Zahl, Datum ...) und die festzulegenden Eigenschaften des Datentyps (Text - Länge der Zeichenkette, Zahl - Byte, Integer, Double usw.), da später nur Daten in das jeweilige Feld eingegeben werden können, die den Eigenschaften entsprechen.
-
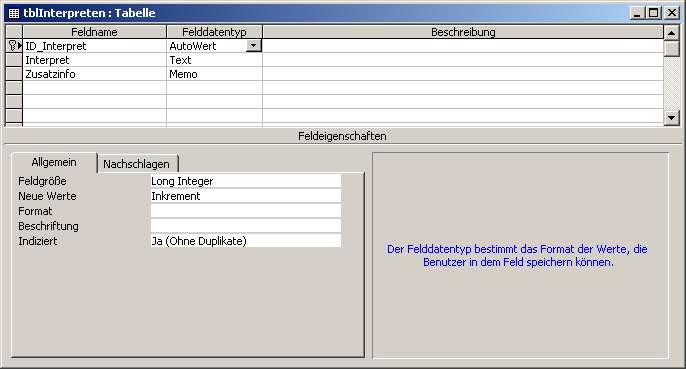
- Entwurfsansicht der Tabelle tblInterpreten. Im unteren Bereich des Fensters werden die Feldeigenschaften des gerade aktiven Feldes angezeigt. In der Abbildung ist das das Feld ID_Interpret.
Ziel der Festlegung der Eigenschaften ist es, die geeigneten Eigenschaften zu finden, die die Anforderungen der Anwendung erfüllen und der Forderung nach Leistungsoptimierung gerecht werden.
Beispiel
In einem Feld zur Angabe des Alters wäre der Datentyp Zahl/Byte angemessen (ganze Zahlen von 0 bis 255), da das Feld nur 1 Byte Speicher belegt und kaum jemand 255 Jahre alt wird. Würde man die Voreinstellung Long Integer belassen, würde jedes Feld 4 Byte Speicher benötigen, egal welcher Wert enthalten ist. Beim Laden der Tabelle würde also allein für das Feld Alter der vierfache Speicherbedarf entstehen.
Index
Ein Index ist ein Feature, das Such- und Sortiervorgänge für eine Tabelle beschleunigt. Der Index wird datenbankintern durch das DBMS gespeichert, was einerseits den Zugriff auf gesuchte Datensätze beschleunigt, andererseits aber auch mehr Speicherplatz für die Datenbank erfordert. Man sollte also nur Felder indizieren, deren Inhalt häufig durchsucht werden wird.
Einen Index können Sie auf zwei Arten aus einem Feld erstellen: In der Entwurfsansicht einer Tabelle im Fenster "Indizes" oder dadurch, dass Sie die Indiziert-Eigenschaft des Feldes auf Ja festlegen.
Bei den Indizes unterscheidet man solche mit Duplikaten und solche ohne Duplikate (also eindeutig identifizierbare Werte).
Primärschlüssel (Primary Key)
Zur eindeutigen Kennzeichnung eines Datensatzes sollte in der Regel in jeder Tabelle ein Feld für einen Primärschlüssel des Typs Autowert verwendet werden. Dieser wird programmintern durch das DBMS erzeugt und verwaltet. So wird es einfacher, Anomalien in der Datenbank zu vermeiden und Beziehungen zwischen Tabellen in der Datenbank herzustellen. Mit Hilfe der Primärschlüssel wird auch die Datenintegrität in der Datenbank geprüft.
Der Primärschlüssel wird in abhängigen Tabellen zum Sekundärschlüssel (Secondary Key).
Man kann zwar auch selbst Primärschlüssel festlegen, indem man sich die Werte selbst ausdenkt oder mehrere Spalten zum Primärschlüssel deklariert, aber das ist fehleranfälliger und umständlicher. Würde man z. B. in einer Adressdatenbank ohne automatisch erzeugten Primärschlüssel Datensätze eindeutig identifizieren wollen, müsste man neben den Namen (die können nämlich gleich und damit nicht mehr eindeutig sein) noch ein weiteres Feld in den Primärschlüssel einbeziehen: z. B. die Adresse, da nicht sofort anzunehmen ist, dass Personen mit gleichen Namen auch die gleiche Adresse haben. Bei der Prüfung des Primärschlüssels auf seine Gültigkeit müssten aber immer die Daten aus mehreren Spalten kontrolliert werden.
Man kann zwischen fortlaufendem und zufälligem Primärschlüsselwert wählen. Ersterer sieht wie eine Nummerierung (Er ist aber keine Nummerierung!) der Datensätze aus. Wird aber ein Datensatz gelöscht, kann der Primärschlüsselwert nicht wieder verwendet werden - die scheinbare "Nummerierung" ist im Eimer. Man sollte sich also um den Wert der automatisch erzeugten Primärschlüssel als "Nummerierer" nicht zu viel Gedanken machen. Denn sobald man Primärschlüssel zur Erstellung von Beziehungen zwischen Tabellen (also als Fremdschlüssel) verwendet, lässt sich an den Primärschlüsselwerten sowieso nichts mehr ändern.
Datenintegrität durch das DBMS überwachen lassen
Beim Festlegen der Beziehungen zwischen Tabellen, kann man das DBMS anweisen, auf Datenintegrität zu achten
-
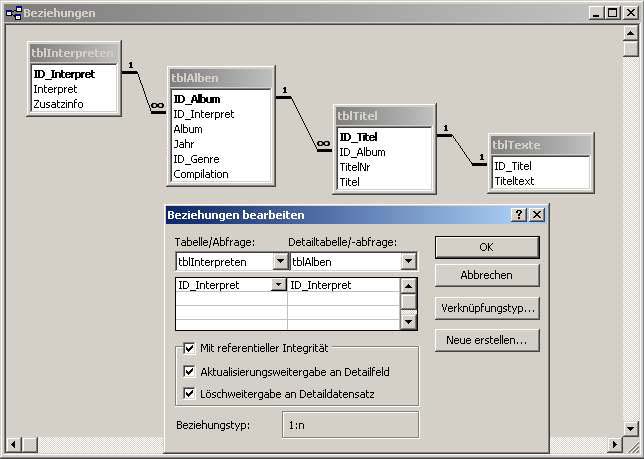
- Festlegen von referenzieller Datenintegrität mit Lösch- und Aktualisierungsweitergabe für die Tabellen tblInterpret und tblAlben
Die Einstellungen in der Abbildung bewirken zweierlei:
- Beim Löschen eines Interpreten werden auch alle seine Alben gelöscht.
- Es ist nicht möglich, ein Album in der Tabelle tblAlben einzugeben, wenn es den entsprechenden Interpreten des Albums in der Tabelle tblAlben nicht gibt.
Die Überwachung der Datenintegrität vermeidet Anomalien in der Datenbank, z. B. können keine so genannten verwaisten Datensätze auftreten, also Alben ohne Interpreten oder Titel ohne Alben.
Ein letzter Hinweis
Die Struktur der Tabellen und die definierten Beziehungen sind das A und O der Datenbank. Änderungen daran vorzunehmen, wenn erst eine Reihe von Abfragen und Formularen erstellt und Code geschrieben ist, kann äußerst mühevoll und fehleranfällig sein.
Im Idealfall sollten die Tabellen und Beziehungen vor dem Erstellen der Abfragen, Formulare, Berichte und dem Schreiben des Codes fertig sein. Dabei ist ein häufiges Problem, dass sowohl Auftraggeber als auch Programmierer nicht genau wissen, welche Anforderungen die fertige Datenbank erfüllen soll. Die meisten Probleme und Missverständnisse erwachsen aus der Tatsache, dass der Auftraggeber wenig vom Programmieren und der Programmierer wenig vom Einsatz der Datenbank im beruflichen Alltag des Auftraggebers weiß. "Machen Sie mal eine Schuldatenbank" ist für einen schulfremden Programmierer eine Aufgabe, die er - allein gelassen - auf keinen Fall zur Zufriedenheit des Auftraggebers lösen wird.