Das relationale Modell
Vorbemerkung
Das relationale Modell geht u.a. auf Forschungsarbeiten von Edgar F. Codd in den 60er und 70er Jahren zurück. Man kann sich sehr lange und ausgiebig mit der Geschichte und der Theorie des relationalen Modells befassen - der entsprechende Wikipedia-Artikel mit der Linksammlung sollte als Anregung gelesen werden. Wir werden uns auf etwas weniger theoretischem Niveau mit Relationen beschäftigen.
Ehe wir uns mit den Relationen beschäftigen, ist noch ein Exkurs zur Datenbanknormalisierung notwendig.
Normalisierung von Daten
Im Grunde geht es bei der Normalisierung der Daten um Folgendes:
- Die Daten sollten atomar vorliegen.
- Es sollte weder Redundanzen noch leere Datenfelder geben.
- Die Abhängigkeiten zwischen den Daten sollten korrekt sein.
Sind diese Anforderungen erfüllt, sollte die Datenbank effektiv und ohne Anomalien funktionieren.
Eine recht gute Beschreibung der Normalisierungstheorie finden Sie in der Wikipedia, wobei Sie auch auf die Terminologie achten sollten.
Hier erfolgt nur eine stark vereinfachte Beschreibung der so genannten Normalformen.
1. Normalform ( = 1. NF)
Daten sollen in Tabellenfelder elementar/atomisiert vorliegen.
Beispiel: Ein Name besteht z. B. aus dem Nach- und Vornamen oder eine Adresse aus Straße, Ort, PLZ, usw., obwohl man natürlich auch alle Angaben in ein Feld namens Adresse schreiben könnte. Die Auswahl von Daten nach dem Kriterium PLZ wäre dadurch aber erheblich erschwert. Die Atomisierung der Daten sollte aber den Anforderungen der Anwendung angemessen sein - für eine Lieferfirma mit automatischer Erstellung von Liefertouren mag die Trennung der Hausnummer von der Straße sinnvoll sein, aber für z. B: eine Schülerdatenbank?
Datenredundanz und Vermeidung leerer Datenfelder
Ehe wir zum Wortlaut zwei weiterer Normalformen kommen, klären wir, wie sie überhaupt entstehen. Wir bleiben am Beispiel der zu erstellenden Musikdatenbank.
Nehmen wir eine anfangs nahe liegende Idee, etwa folgende Tabelle zu verwenden:
-
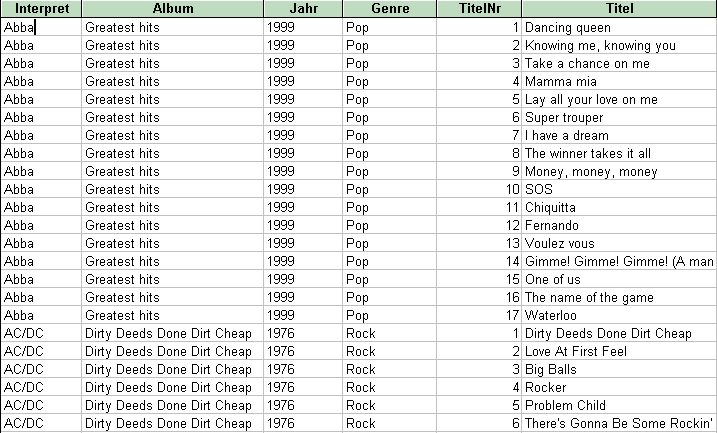
- Beispieltabelle mit redundanten Daten
Wie Sie sehen, sind die Angaben Interpret, Album, Jahr und Genre redundant: Sie erscheinen so oft, wie es Titel auf dem Album gibt. In einer kleinen Datenbank für Zuhause mag das ja angehen, aber für eine kommerzielle Großanwendung mit Millionen von Datensätzen ist das keine praktikable Lösung: Es gibt einfach zu viele Redundanzen.
Man könnte das Problem auf folgende Art und Weise lösen:
-

- Modell einer Beispieltabelle mit leeren Datenfeldern
Jetzt gibt es aber leere Datenfelder, denn nicht alle Alben haben die gleiche Anzahl von Titeln. Das Beispiel mag etwas gekünstelt wirken, denn man merkt sehr schnell, dass Spalten für Titel1, Titel2 usw. keine Lösung sind, aber müsste man eine Datenbank mit internationalen Namen machen, würde man über eine allgemein gültige Aufteilung der Spalten ins Überlegen kommen: Was macht man bei mehreren Vornamen? Was macht man mit apellido materno/paterno usw. usf.?
Die Lösung der Probleme mit den Redundanzen bzw. mit den leeren Datenfeldern liegt in der Verwendung mehrerer Tabellen, die über Schlüssel miteinander verknüpft sind.
-
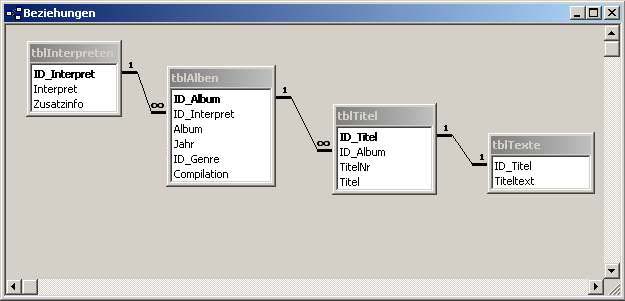
- Beispiel für aufgeteilte Tabellen, die über Schlüssel miteinander verbunden sind
Im Beispiel erhält jeder Interpret zu seiner Identifikation einen Primärschlüssel mit dem Namen ID_Interpret (automatisch verwaltet vom DBMS).
In der Tabelle mit den Alben erscheint ID_Interpret als Sekundärschlüssel. Über den Primärschlüssel ID_Album wird das Album identifiziert, über den Sekundärschlüssel ID_Interpret der entsprechende Interpret.
Nach dem gleichen Prinzip werden die Tabellen mit den Titeln und Texten verknüpft.
Die Tabellen stehen dabei zueinander in unterschiedlichen Beziehungen, was durch die gleich zu besprechenden Relationen repräsentiert wird.
Die aufgeteilten Tabellen entsprechen der 2. und 3. Normalform.
2. Normalform ( = 2. NF)
Eine Relation ist in zweiter Normalform, wenn die erste Normalform vorliegt und alle Nichtschlüsselattribute von jedem Schlüsselkandidaten voll funktional abhängig sind.
Diese Definition klingt etwas kompliziert, ist aber gar nicht so schwer zu verstehen: Ein Album ist komplett vom Interpreten abhängig, ein Titel komplett vom Album mit Jahr und Genre, nicht nur vom Jahr oder Genre, und der Text ist vom Titel abhängig usw. Dabei wechselt in der Hierarchie der Daten die Funktion: ID_Album ist in Bezug auf den Interpreten ein Nichtschlüsselattribut, in Bezug auf die Titel des Albums ist die ID_Album hingegen der Schlüsselkandidat.
3. Normalform ( = 3. NF)
Die 3. NF ist erfüllt, wenn zwischen Spalten, die nicht den Primärschlüssel bilden, keine Abhängigkeiten bestehen.
Im Wikipedia-Artikel wird das anhand der Spalte Gründungsjahr für eine Band erläutert: Das Gründungsjahr wäre in der Tabelle mit den Alben falsch - es gehört als Primärinformation in die Tabelle mit den Interpreten. Solche Fehler sind meist offensichtlich und werden selten gemacht.
Relationen
Mit Hilfe von Datenbanken versucht man, bestimmte Bereiche der Realität abzubilden. Die an den Objekten der Realität beobachteten Beziehungen werden in zweidimensionalen Tabellen nachgebildet. Dabei ergeben sich unterschiedliche Beziehungstypen (=Relationen) zwischen den Tabellen. Diese Relationen helfen beim Normalisieren der Daten.
Die 1:n-Beziehung
Die 1:n-Beziehung ist eigentlich die häufigste Beziehung: Zu einem Primärdatensatz der Haupttabelle gibt es mehrere abhängige sekundäre Datensätze in der abhängigen Tabelle. Zum Beispiel:
- ein Schüler besucht mehrere unterschiedliche Kurse
- eine Bestellung enthält mehrere Artikel
- eine Band produziert mehrere Alben
- ein Album enthält mehrere Titel
Am letzten Beispiel sieht man, dass in einer komplexen Datenbank ein Datensatz sowohl sekundär als auch primär sein kann: In Bezug auf die Band ist das Album sekundär, hingegen in Bezug auf die Titel des Albums ist es primär.
Die 1:1-Beziehung
Zu jedem Primärdatensatz gibt es genau einen Sekundärdatensatz:
- von einem Schüler gibt es ein Foto für den Schülerausweis
- ein Titel hat einen Text
Manchmal teilt man Datensätze in verschiedene Tabellen auf, um die Leistung der Datenbank zu verbessern: Wenn man eine Tabelle öffnet, wird sie komplett in den Arbeitesspeicher geladen. Lagert man selten benötigte und speicherintensive Daten (z. B. Fotos von Schülern) in eine 1:1-Tabelle, arbeitet die Datenbank schneller.
Die n:m-Beziehung
Einem Datensatz in einer ersten Tabelle sind n Datensätze in einer zweiten Tabelle zugeordnet und gleichzeitig sind den Datensätzen der zweiten Tabelle m Datensätze in der ersten Tabelle zugeordnet.
Beispiele:
- Ein Buch ist von mehreren Autoren geschrieben, die wiederum weitere unterschiedliche Bücher geschrieben haben.
- Ein Album wurde von verschiedenen Interpreten aufgenommen, die wiederum weitere unterschiedliche Alben produziert haben.
Das Problem lässt sich nur mit einer Hilfstabelle lösen, die die Primärschlüssel beider Tabellen enthält. Für das Musikbeispiel könnte die Lösung so aussehen:
-
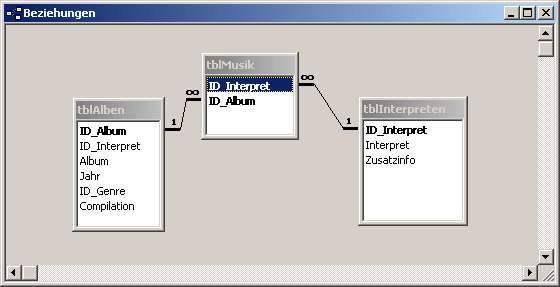
- Beispiel für aufgeteilte Tabellen mit einer n:m-Beziehung
Durch die Verknüpfung mit Hilfe der Tabelle tblMusik lassen sich zu einem Interpreten verschiedene Alben, aber auch zu einem Album verschiedene Interpreten zuordnen. Dabei bleibt die Kombination von ID_Interpret und ID_Album eindeutig - man spricht von einem zusammengesetzten Schlüssel. Natürlich könnte man auch einen weiteren Primärschlüssel hinzufügen.
Hinweis
In der von Ihnen zu entwickelnden Musikdatenbank verzichten wir zur Vereinfachung auf die Implementierung der n:m-Beziehung, denn dadurch erhöht sich der Programmieraufwand bei Schreibzugriffen auf Abfragen über mehrere Tabellen. Das ist zwar nicht weiter problematisch, erfordert aber mehr Zeit, die wir leider nicht haben.
Sollte es Kompilationen in der Datenbank geben, helfen wir uns eben mit Notlösungen.